OpenAI представил бенчмарк для медицинских компетенций LLM
12.05.25
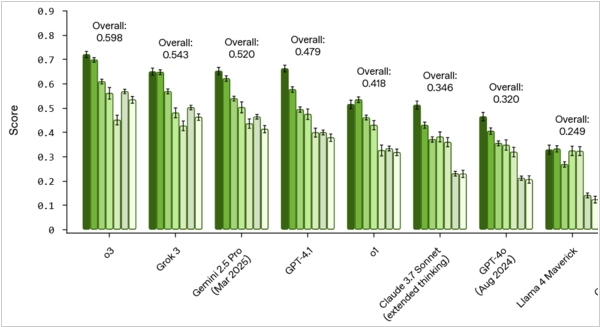
Люди все чаще обращаются к чат-ботам за медицинскими советами, но пока общественное (и регуляторное) отношение к этому не определено. Сами разработчики LLM учат своих ботов, отвечая на медицинские вопросы, делать дисклеймер, что "мои советы не могут заменить доктора", но в целом, считают такие медицинские консультации нормальными, зная о неизбежных галлюцинациях, которые уже привели к парочке скандалов из-за опасно-ошибочных ответов. OpenAI сегодня даже представил HealthBench - бенчмарк, который оценивает качество медицинских ответов LLM моделей. Он включает 5000 реалистичных медицинских бесед, составленных и проверенных 262 врачами, и тестируемая LLM должна угадывать правильные ответы врача в этих беседах. Кроме того, компания провела тестирование ведущих моделей, и, конечно, победителем оказалась O3 от OpenAI, на втором месте Grok, на третьем Gemini.
